
URL چیست؟ این مقاله به معرفی URL (Uniform Resource Locator) میپردازد و ساختار و عملکرد آن را توضیح میدهد. در این مقاله، شما با مفهوم URL و نحوه عملکرد آن در وب آشنا خواهید شد.
URL (Uniform Resource Locator) آدرسی است که به یک منبع خاص در اینترنت اشاره میکند. این یکی از مکانیزمهای کلیدی است که مرورگرها برای دسترسی به منابع منتشر شده مانند صفحات HTML، اسناد CSS، تصاویر و غیره از آن استفاده میکنند.
در تئوری، هر URL معتبر به یک منبع منحصر به فرد اشاره میکند. در عمل، برخی استثناها وجود دارند، مانند URLهایی که به منابعی اشاره میکنند که دیگر وجود ندارند یا جابجا شدهاند. از آنجا که منابع توسط وب سرور مدیریت میشوند، مسئولیت مدیریت صحیح این منابع و URLهای مرتبط به عهده وب سرور است.
اصول: ساختار URL

چند نمونه از URLها:
- https://developer.mozilla.org
- https://developer.mozilla.org/en-US/docs/Learn/
- https://developer.mozilla.org/en-US/search?q=URL
هر یک از این URLها را میتوان در نوار آدرس مرورگر تایپ کرد تا منبع مرتبط با آن بارگذاری شود که در هر سه مورد یک صفحه وب است.
یک URL از بخشهای مختلفی تشکیل شده است، برخی اجباری و برخی اختیاری. مهمترین بخشها در URL زیر برجسته شدهاند:
Scheme (طرح)

اولین بخش URL Scheme است که پروتکلی را مشخص میکند که مرورگر باید برای درخواست منبع استفاده کند. پروتکل معمولاً HTTPS یا HTTP است. Schemeهای دیگری مانند mailto: نیز وجود دارند که برای باز کردن برنامه ایمیل استفاده میشوند.
Authority (مرجع)

مرجع به وسیله الگوی :// از Scheme جدا میشود. اگر وجود داشته باشد، مرجع شامل دامنه (مثلاً www.example.com) و پورت (مثلاً 80) است که با یک دو نقطه از هم جدا میشوند.
- دامنه: مشخص میکند کدام وب سرور در حال درخواست است. معمولاً یک نام دامنه است، اما میتواند یک آدرس IP نیز باشد.
- پورت: “gate” فنی برای دسترسی به منابع وب سرور را نشان میدهد. اگر وب سرور از پورتهای استاندارد HTTP (پورت 80 برای HTTP و 443 برای HTTPS) استفاده کند، معمولاً پورت ذکر نمیشود.
مسیر به منبع

/path/to/myfile.html مسیر به منبع روی وب سرور است. این مسیر میتواند یک موقعیت فیزیکی روی سرور باشد یا بیشتر یک انتزاع است که توسط وب سرور مدیریت میشود.
پارامترها
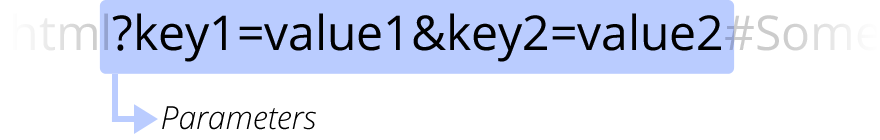
?key1=value1&key2=value2 پارامترهای اضافی هستند که به وب سرور ارائه میشوند. این پارامترها به صورت زوجهای کلید/مقدار با علامت & جدا میشوند.
انکر

#SomewhereInTheDocument انکر به بخش دیگری از منبع است. انکر یک نوع “bookmark” درون منبع است که به مرورگر جهت نمایش محتوا در نقطه مشخص شده توسط انکر را میدهد.
نحوه استفاده از URLها
هر URL را میتوان مستقیماً در نوار آدرس مرورگر تایپ کرد تا به منبع مرتبط دسترسی پیدا کند. زبان HTML به طور گستردهای از URLها استفاده میکند:
- برای ایجاد لینک به اسناد دیگر با استفاده از عنصر
<a>. - برای لینک کردن یک سند به منابع مرتبط با استفاده از عناصری مانند
<link>یا<script>. - برای نمایش رسانههایی مانند تصاویر (با استفاده از عنصر
<img>)، ویدئوها (با استفاده از عنصر<video>)، صدا و موسیقی (با استفاده از عنصر<audio>). - برای نمایش اسناد HTML دیگر با استفاده از عنصر
<iframe>.
URLهای مطلق در مقابل URLهای نسبی
آنچه که در بالا دیدیم، URL مطلق نامیده میشود، اما همچنین چیزی به نام URL نسبی نیز وجود دارد. استاندارد URL هر دو را تعریف میکند — اگرچه از اصطلاحات رشته URL مطلق و رشته URL نسبی استفاده میکند تا آنها را از اشیای URL (که نمایشهای در حافظه URLها هستند) متمایز کند.
بیایید تفاوت بین مطلق و نسبی را در زمینه URLها بررسی کنیم.
بخشهای مورد نیاز یک URL به میزان زیادی به زمینهای که URL در آن استفاده میشود، بستگی دارد. در نوار آدرس مرورگر شما، یک URL هیچ زمینهای ندارد، بنابراین باید یک URL کامل (یا مطلق) ارائه دهید، مانند آنهایی که در بالا دیدیم. نیازی به شامل کردن پروتکل (مرورگر به صورت پیشفرض از HTTP استفاده میکند) یا پورت نیست (که فقط زمانی لازم است که وب سرور هدف از یک پورت غیرمعمول استفاده کند)، اما سایر بخشهای URL ضروری هستند.
هنگامی که یک URL در داخل یک سند استفاده میشود، مانند یک صفحه HTML، اوضاع کمی متفاوت است. از آنجا که مرورگر قبلاً URL خود سند را دارد، میتواند از این اطلاعات برای پر کردن بخشهای گمشده هر URL موجود در داخل آن سند استفاده کند. ما میتوانیم بین یک URL مطلق و یک URL نسبی تنها با نگاه کردن به بخش مسیر URL تمایز قائل شویم. اگر بخش مسیر URL با کاراکتر “/” شروع شود، مرورگر آن منبع را از ریشه سرور بارگیری میکند، بدون توجه به زمینهای که توسط سند فعلی داده شده است.
بیایید برخی مثالها را برای روشنتر شدن این موضوع بررسی کنیم. فرض کنیم که URLها از داخل سندی تعریف شدهاند که در URL زیر قرار دارد: https://developer.mozilla.org/en-US/docs/Learn.
https://developer.mozilla.org/en-US/docs/Learn خود یک URL مطلق است. این URL تمام بخشهای ضروری برای مکانیابی منبعی که به آن اشاره میکند را دارد.
تمام URLهای زیر نسبی هستند:
- URL نسبی طرح:
//developer.mozilla.org/en-US/docs/Learn— فقط پروتکل گمشده است. مرورگر از همان پروتکلی که برای بارگیری سند میزبان آن URL استفاده شده است، استفاده خواهد کرد. - URL نسبی دامنه:
/en-US/docs/Learn— پروتکل و نام دامنه هر دو گمشدهاند. مرورگر از همان پروتکل و همان نام دامنهای که برای بارگیری سند میزبان آن URL استفاده شده است، استفاده خواهد کرد. - زیرمنابع:
Common_questions/Web_mechanics/What_is_a_URL— پروتکل و نام دامنه گمشدهاند و مسیر با / شروع نمیشود. مرورگر سعی خواهد کرد سند را در یک زیرشاخه از آن که شامل منبع فعلی است، پیدا کند. در این مورد، ما واقعاً میخواهیم به این URL برسیم:https://developer.mozilla.org/en-US/docs/Learn/Common_questions/Web_mechanics/What_is_a_URL. - بازگشت به شاخه دایرکتوری:
../CSS/display— پروتکل و نام دامنه گمشدهاند و مسیر با...شروع میشود. این از دنیای سیستم فایل UNIX به ارث رسیده است — تا به مرورگر بگوید که میخواهیم به یک سطح بالاتر برویم. در اینجا ما میخواهیم به این URL برسیم:https://developer.mozilla.org/en-US/docs/Learn/../CSS/display، که میتوان آن را ساده کرد به:https://developer.mozilla.org/en-US/docs/CSS/display. - فقط انکر:
#semantic_urls— همه بخشها به جز انکر گمشدهاند. مرورگر از URL سند فعلی استفاده کرده و بخش انکر را به آن اضافه یا جایگزین میکند. این زمانی مفید است که میخواهید به بخش خاصی از سند فعلی لینک بدهید.
در اینجا یک مثال HTML ساده آورده شده که شامل استفاده از URLهای مطلق و نسبی است:
<!DOCTYPE html>
<html lang="fa">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>مثال URLهای مطلق و نسبی</title>
</head>
<body>
<h1>مثال URLهای مطلق و نسبی</h1>
<p>این یک لینک به یک URL مطلق است:</p>
<a href="https://developer.mozilla.org/en-US/docs/Learn">آموزش در MDN</a>
<p>این یک لینک به یک URL نسبی طرح است:</p>
<a href="//developer.mozilla.org/en-US/docs/Learn">آموزش در MDN (نسبی طرح)</a>
<p>این یک لینک به یک URL نسبی دامنه است:</p>
<a href="/en-US/docs/Learn">آموزش در MDN (نسبی دامنه)</a>
<p>این یک لینک به یک زیرمنبع است:</p>
<a href="Common_questions/Web_mechanics/What_is_a_URL">What is a URL?</a>
<p>این یک لینک به یک دایرکتوری بالاتر است:</p>
<a href="../CSS/display">نمایش CSS</a>
<p>این یک لینک به یک انکر در همین صفحه است:</p>
<a href="#section2">برو به بخش ۲</a>
<h2 id="section2">بخش ۲</h2>
<p>این بخش دوم است که به آن از طریق انکر لینک دادیم.</p>
</body>
</html>
در این مثال، لینکهای مختلف با استفاده از URLهای مطلق و نسبی نمایش داده شدهاند:
- لینک اول از URL مطلق استفاده میکند.
- لینک دوم از URL نسبی طرح استفاده میکند.
- لینک سوم از URL نسبی دامنه استفاده میکند.
- لینک چهارم از URL نسبی به یک زیرمنبع استفاده میکند.
- لینک پنجم از URL نسبی برای بازگشت به یک دایرکتوری بالاتر استفاده میکند.
- لینک ششم به یک انکر در همان صفحه لینک میدهد.
نمودار زیر مقایسهای بین URL، URI و URN را نشان میدهد.
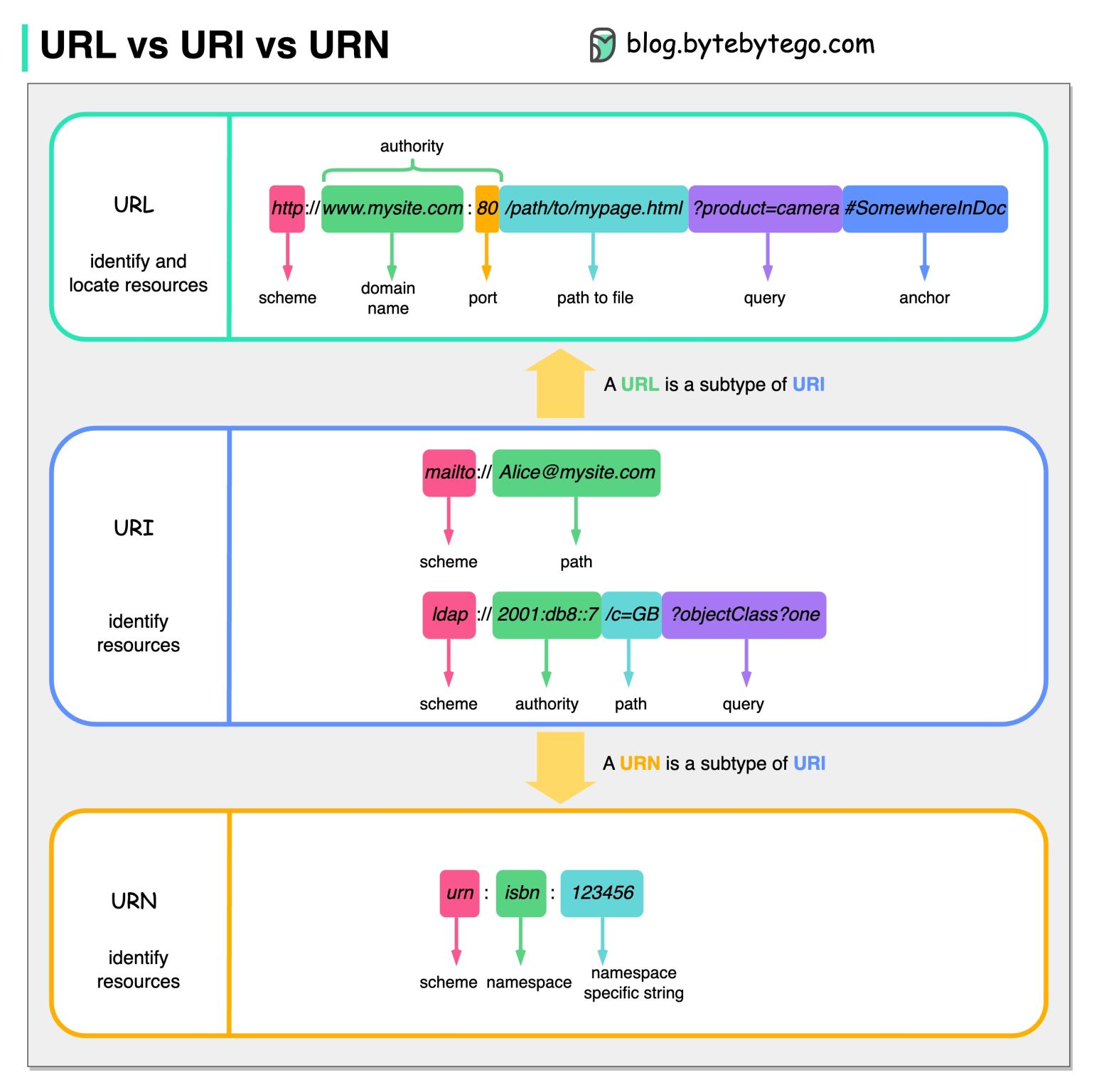
URI
URI مخفف Uniform Resource Identifier (شناسه یکنواخت منابع) است. این شناسه یک منبع منطقی یا فیزیکی را در وب شناسایی میکند. URL و URN زیرمجموعههای URI هستند. URL یک منبع را مکانیابی میکند، در حالی که URN یک منبع را نامگذاری میکند.
URL
URL مخفف Uniform Resource Locator (مکانیاب یکنواخت منابع) است، که مفهوم کلیدی HTTP محسوب میشود. این آدرس یک منبع یکتا در وب است. URL میتواند با پروتکلهای دیگری مانند FTP و JDBC نیز استفاده شود.
URN
URN مخفف Uniform Resource Name (نام یکنواخت منابع) است. این نوع از شناسه از اسکیم urn استفاده میکند. URNها نمیتوانند برای مکانیابی یک منبع استفاده شوند. یک مثال ساده که در نمودار آورده شده است، از یک فضای نام و یک رشته خاص به فضای نام تشکیل شده است.




